
La relación entre el diseño de la red, el hardware subyacente y la jerarquía de memoria desafían la suposición común de que menos FLOPs y una reducción en el número de parámetros o capas automáticamente lleva a una mayor eficiencia energética.
Dimensión de la red y eficiencia energética
Cuando una red neuronal se dimensiona adecuadamente en relación con la memoria caché del sistema, se optimizan los accesos a la memoria, lo que reduce drásticamente el costo energético asociado al entrenamiento. Esto sucede porque el acceso a niveles superiores de memoria (RAM o disco) es mucho más lento y consume más energía que la memoria caché más cercana al procesador.
Factores clave:
Tamaño de la caché: Los ordenadores tienen jerarquías de memoria que incluyen múltiples niveles de caché (L1, L2, L3) además de a la RAM principal. Cada nivel tiene una capacidad y velocidad distintas. Una red con un tamaño de parámetros ajustado al rango de 1x a 2x el tamaño de una caché específica es capaz de mantener la mayoría de sus operaciones dentro de la misma, minimizando accesos energéticamente costosos a otros niveles de memoria.
Relaciones inter-capa: Las redes pequeñas, con capas muy anchas, pueden generar conjuntos de datos intermedios (activaciones y gradientes) que no caben en la caché, obligando a realizar operaciones con la RAM. Esto introduce una penalización energética significativa.
Eficiencia operativa del hardware: El hardware, como las GPUs y CPUs, tiene un ancho de banda y capacidad de paralelismo óptimos para ciertos tamaños de red. Si la red es demasiado pequeña, el hardware puede operar muy por debajo de su capacidad, desperdiciando energía en ciclos de procesamiento inactivos.
Fuente: Artículo Measuring the Energy Consumption and Efficiency of Deep Neural Networks: An Empirical Analysis and Design Recommendations
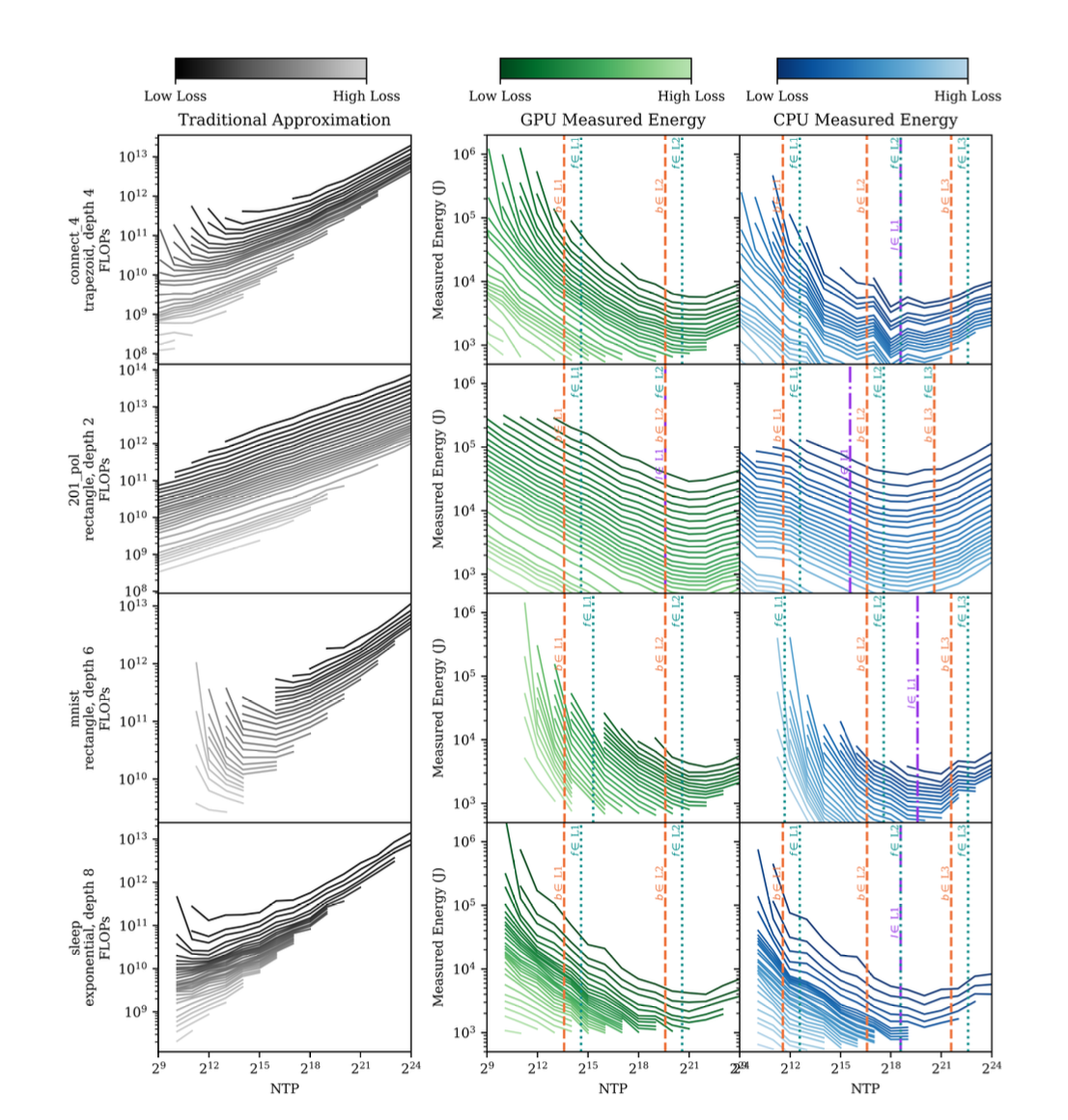
Ejemplo práctico: Redes MLP
Los perceptrones multicapa (MLP) son un caso de estudio clave:
En una MLP, los pesos y las activaciones de cada capa deben almacenarse temporalmente durante las operaciones de retropropagación.
Si el número de parámetros de entrenamiento (NTP) se ajustan a 1x o 2x el tamaño de la caché, la mayoría de los cálculos y transferencias de datos se realizan dentro de la caché, logrando una alta eficiencia.
Para redes con NTP demasiado pequeñas, los recursos de hardware pueden no estar plenamente utilizados, resultando en un bajo rendimiento energético por operación.
Beneficios de ajustar las redes a las cachés
Reducción de latencias: Se minimizan los tiempos de acceso a memoria al mantener las operaciones dentro de niveles rápidos de la caché.
Uso equilibrado del hardware: Aprovechar al máximo las capacidades de paralelismo y acceso rápido de las CPUs o GPUs.
Consumo energético optimizado: Al evitar accesos frecuentes a memoria externa, el consumo energético por parámetro y por operación se reduce notablemente.
Conclusión
Esto se ha observado en una arquitectura de redes neuronales específica, para la que habría que dimensionar redes neuronales según el tamaño de la caché del sistema no solo mejora la eficiencia energética, sino que también maximiza el rendimiento del hardware. Aunque habría que evaluar otras arquitecturas clave (LLMs, CNNs, GNNs,…), este enfoque subraya la importancia de un diseño consciente de la arquitectura en la IA sostenible, ofreciendo un camino claro para reducir el impacto ambiental del aprendizaje profundo.
Fuente: Charles Edison Tripp, Jordan Perr-Sauer, Jamil Gafur, Ambarish Nag, Avi Purkayastha, Sagi Zisman, Erik A. Bensen. (2024). Measuring the Energy Consumption and Efficiency of Deep Neural Networks: An Empirical Analysis and Design Recommendations. Arxiv.